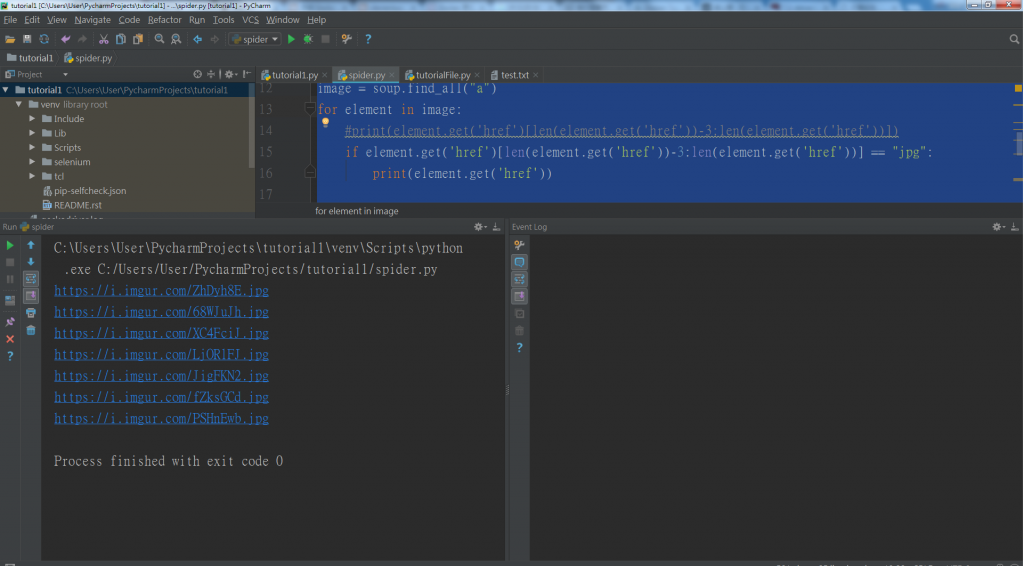
把所有圖片的連結過濾抓出來
可以這樣做
# coding=utf-8
from selenium import webdriver
import urllib2
from bs4 import BeautifulSoup
driver = webdriver.Firefox()
driver.get("https://www.ptt.cc/bbs/Beauty/M.1515902682.A.579.html")
#print(driver.page_source)
soup = BeautifulSoup(driver.page_source, 'html.parser')
#print(soup)
image = soup.find_all("a")
for element in image:
#print(element.get('href')[len(element.get('href'))-3:len(element.get('href'))])
if element.get('href')[len(element.get('href'))-3:len(element.get('href'))] == "jpg":
print(element.get('href'))
#print(image)
driver.close()
我的作法是判斷出字串後面的結尾是圖片就把她過濾出來
如下圖: